AI in Video Games, boiled down. Part I.
A downloadable guide
Welcome to the “AI in Video Games, boiled down” series!
These series discuss the logic behind AI in video games, and explain how you could go about implementing it, as well as point to the resources you could use. My hope is that these series will help you decide which AI approaches you should pick for your game, where to find the resources and implementations for it, and write the code in a way that will make it possible to incorporate the AI painlessly into your games. It is important that you know how to code and keep in mind what you expect your AI to do in your games.
Part I aims to introduce the basics of the AI terminology, and give you the feel of what AI is all about. These concepts are universal and are not tied to a specific game genre, so they will be applicable for your games as well! Exciting stuff. Well, what are we waiting for? Onwards!
The Basics.
First off, let’s briefly discuss what AI in games is supposed to achieve - we want our computer-controlled players, monsters, NPC’s, etc. to act intelligently. The concept of intelligence, believe it or not, is a topic of many heated discussions, and AI researchers cannot for the life of them agree on one single term - just take a look at the first sentence in the wikipedia article. Yeah, it is that bad. In either case, if you are interested in some philosophical debates about intelligence and conscience, take a look at the Turing Test, Chinese Room Experiment and if you want something even more mind-stimulating, at the Physical Symbol System.
In our case though, we can opt for a simpler approach - let us simply consider our AI intelligent if, after processing the state it is in, it opts to perform the action that will benefit itself the most - e.g. will result in the biggest reward. Look at the bolded words. These terms will be popping up everywhere when you study AI (as well as in these series), so let’s take some time to understand what exactly they are.
State - this is all of the available and relevant information to your AI. This information is highly dependent on the context, which in our case is the game, and can take many forms (which we will take a look at later on). It is up to the game designer to decide what information is available to the AI. In some games (think chess, tic-tac-toe, etc.) the entire environment is fully observable, and hence, available to all parties at all times. In others (shooters, RTS, etc.) some of the information is hidden - say the location of enemy units in Fog of War or behind the cover. The AI should also expect the information to be relevant to the decision making process, because… well, we do not want our AI to process useless data.
What do you think the state of a game would be in Tic-Tac-Toe?
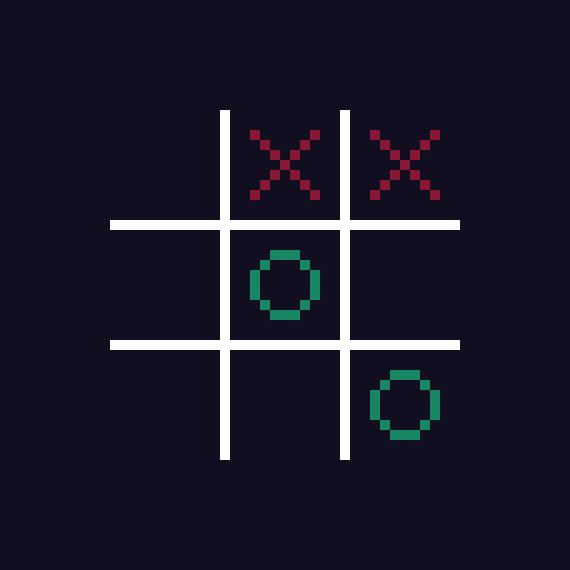
The classic Tic-Tac-Toe. Before AI decides where to make its next move, gotta understand what state it is in.
For this particular board, we might want to include information about the X's and O's, their locations as well as the empty spots - in the end of the day, that is all we need to make a smart next move. In practice, a simple array of length 9 would suffice, something along the lines of: [0,x,x,0,o,0,0,0,o] . Zeroes indicate empty spots in our game, "x" are for locations of... X's and "o" is for O's. The array starts at the top-left corner of the "board", and ends at the bottom-right one.
The way you represent your state/action/reward in your AI is called, well, representation. There are many ways of doing that - in the case of the state above, you could make a 2D array, a dictionary, use integers instead of strings or even images. Do go for KISS approach though, that will save you a lot of headache in the long run. When choosing a representation you should usually consider how easily the code and the AI can derive the information about the state and very importantly, the computational complexity. We will talk about it soon, so do not worry about it for now.
Action - at the end of the day, all we want is for our AI to do something. The action is hence the output of the AI’s thinking process. We want actions that the AI commits to perform to be legal (e.g. allowed in your game and in the given state) and logical (e.g. intelligent). An action could be anything from simply moving a piece in the game of chess, picking what building to queue next, deciding on the plan of attack in a strategy game, what skill to use in a RPG battle, etc.
It is usually the state that dictates the possible actions: the state of the Tic-Tac-Toe board above, for example, shows which legal actions we have available - it is all the zeroes in our array! So, we could simply choose any of the available positions in the array, and put an X or O in there, and call it a day. That... would not be very intelligent though, right? We need to know which of the actions will give us the best outcome. E.g. we need to know about the reward.
Reward - in itself, reward is an incentive for our AI’s action. Rewards can be both positive and negative. Usually we would want our AI to hunt down actions that will lead to the highest rewards and avoid the negative ones. Just like in real life! To simplify matters, rewards are usually assigned to the states - we can usually estimate how good a given state is based on the game we are playing.
In the Tic-Tac-Toe example, we could assign reward of 0 for any non-winning state, 1 for the winning ones, and -1 for the losing ones (from the AI's perspective, of course). In chess, we could give a score to the state using the number of pieces the AI and the opponent has. In an RPG, you could use health of your party members, number of enemies remaining etc. It really depends on the game you are working on and what behaviour you want your AI to have!
To make sure that the grading is accurate and represents the states accurately, you can use what is known as a weighted sum method. You could have already thought of that when I mentioned scoring the state of a chess board based on the number of pieces remaining - that is not really correct, is it? It is like saying that having two pawns or two knights are equally good pieces to have! To fix that problem, we can assign an importance weight to those pieces - let's say a Pawn is worth 1, Knight and Bishop - 3, Rook - 5, Queen - 9. To calculate the score of the chess board we would simply need to add numbers of pieces, each multiplied by their relative importance. Now a board where you have only two pawns would be worth: 2 Pawns * 1 = 2 points, while a board with 2 Knights would be: 2 Knights * 3 = 6 points.
When thinking about the weighted sum for your games, pay attention to what you think should be important for your AI - as it will change its behaviour! In a turn-based combat game, if you assign more weight to the health of AI units, it will play the game more defensively; if you assign more weight to the health of enemy troops (or more accurately, the lack of it), then AI would be more aggressive in its attacks. Finding the correct parameter values for your AI is known as hyperparameter optimisation and oh boy, it can be quite a headache. Belive it or not, people have made an AI to optimise AI's. When starting out, experimenting with these values is vital - you might see your AI exhibit some unexpected behaviours, which in some cases, might be helpful.
There is one problem here though - sometimes it is difficult to assign a score to the states properly. Take a look at the board below.
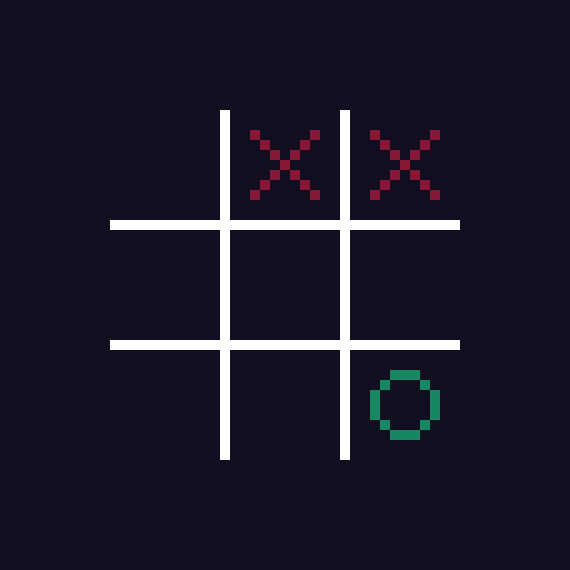
It is AI's turn to place an O. Well, it is obvious, isn't it?
Placing a O in the top-left corner is the best option, as it allows AI to avoid losing the game. But since we have decided to grade all non-terminal (e.g. non-losing and non-winning) states 0, AI could place O anywhere, and pat itself on the back for the smart move. Scoring of these intermediate states is a known problem in the AI, and can be solved differently, depending on the game, the AI model, etc.
Here, let us take a step back, and ask ourselves - how does a chess/strategy/shooter human player thinks when making decision in games? We examine the board/surroundings/environment, consider what moves we could make, what the possible outcomes would be, and pick the best one. This is the very same logic we have used for our AI so far! The only difference is that the human players consider several moves in advance, e.g. we plan ahead. We could indeed apply the same logic to our AI!
So, before making a move, we can consider to which state it will lead, from which we can predict the opponent's move (since we expect the opponent to also play intelligently), then see which states we can reach from there and then... well, we can go as many layers deep as we want. Or can. With some games, that is quite easy, like in Tic-Tac-Toe - every move made decreases potential moves by one, so you could predict everything in advance. In others, like chess, it is not that easy - imagine trying to check all possible moves for all the pieces you have, then for each of those moves how the opponent might react with all potential moves that their pieces have... That will require a ton of computational power and memory.
You might have heard about Deep Blue winning a match of chess against Gary Kasparov, then reigning world champion. That AI used the exact same logic we described in the previous paragraph! With a few bangs and whistles attached, of course. It evaluated 200 million chess positions per second, 30 billion positions per move, considering the moves effects 14 moves into the future routinely. But, believe it or not, the core of that "AI" was indeed a simple matter of giving a score to the states, considering the potential moves, and planning ahead in exactly the same manner as we discussed above. This historical match has many interesting highlights, so take a peek at this excellent piece if you want more details.

According to a Tweet which I cannot find anymore (so it might as well just be my brain whirring up some non-existent memories, so please do not quote me on this) developers of Civilization IV shoved in the entire AI of computer players into a do_ai() function. I think that is pretty funny. Anywho, just wanted to break the wall of text with a picture and a story. Where were we at?
The approaches we have discussed so far is known as Classical AI - which in a nutshell, is... well, a fancy search algorithm. They are plagued by a number of problems: it can be hard to simulate new states, it can be too computationally expensive to calculate smart moves, some states can be difficult to meaningfully incorporate into your rewards calculations or your game might simply require a more eloquent and flexible solution. Welp, we are still going to take a look at them in the next chapter of these series, because they still can be very useful in some situations.
But this is it, folks! For now, at least. Next chapter is going to be about the classical AI, and I am whipping up a Unity project that you can review at your leasure, poke the code and play with parameters to get different behaviours. See you then!
Tips and tricks.
You do not always need an AI to do AI's job. There a number of algorithms, or downright stupid solutions that will do the trick, and will be faster and/or cheaper to implement. My advice - consider alternatives first before you decide to write your AI.
The Deep Blue used the algorithm known as MinMax. You can actually go ahead and start playing with it right ahead, since everything you need to know about it it described above and there loads of resources online that can help you out with writing it yourself from scratch, but I would advise to start with Sebastian Lague's video.
As a rule of thumb, whenever you are writing a piece of code that will be used in your AI, chances are that it will be used extensively, so if you can optimize something in it, do it. The array we used in Tic-Tac-Toe game for the state representation used strings - not exactly the best way of doing it. Using char or short types will save us 2 bytes per element in the array, and probably will result in faster computation times.
If your game incorporates uncertainties in the decision making (e.g. the attack has 80% chance to land), you can incorporate it into your rewards system. The easiest way to do so is to multiply either your action, or the potential resulting state by the probability value. For example, your AI has two choices, to attack with 95% chance to deal 10 damage, or to use a skill that with 50% chance will deal a critical damage of 20. You could then score the first action as 0.95 * 10 = 9.5 and the second one as 0.5*20 = 10. Now, when calculating the rewards for the resulting states, you can use these adjusted values instead.

Leave a comment
Log in with itch.io to leave a comment.